Configure Cluster Health Monitor Settings
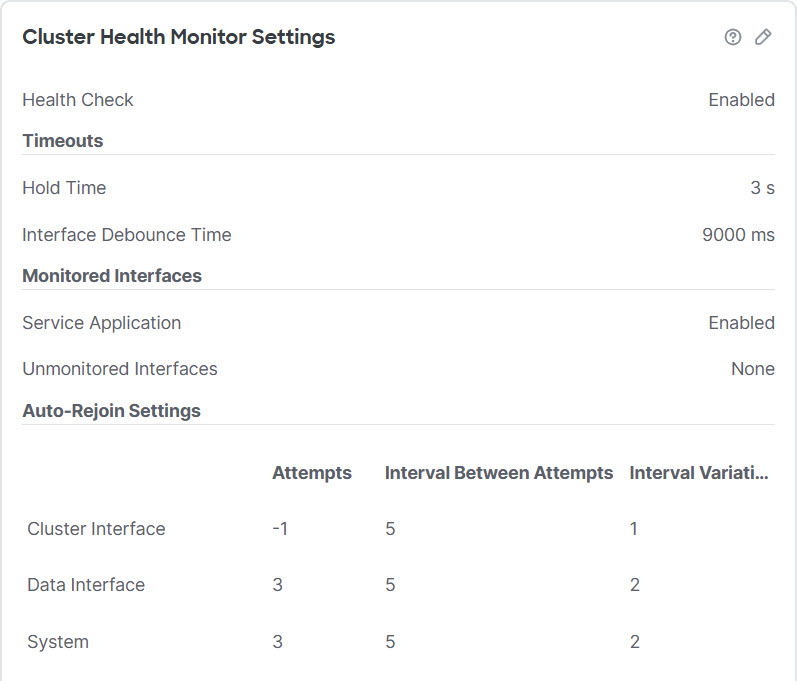
The Cluster Health Monitor Settings section of the Cluster page displays the settings described in the table below.
|
Field |
Description |
|---|---|
|
Timeouts |
|
|
Hold Time |
Between .3 and 45 seconds; The default is 3 seconds. To determine node system health, the cluster nodes send heartbeat messages on the cluster control link to other nodes. If a node does not receive any heartbeat messages from a peer node within the hold time period, the peer node is considered unresponsive or dead. |
|
Interface Debounce Time |
Between 300 and 9000 ms. The default is 500 ms. The interface debounce time is the amount of time before the node considers an interface to be failed, and the node is removed from the cluster. |
|
Monitored Interfaces |
The interface health check monitors for link failures. If all physical ports for a given logical interface fail on a particular node, but there are active ports under the same logical interface on other nodes, then the node is removed from the cluster. The amount of time before the node removes a member from the cluster depends on the type of interface and whether the node is an established node or is joining the cluster. |
|
Service Application |
Shows whether the Snort and disk-full processes are monitored. |
|
Unmonitored Interfaces |
Shows unmonitored interfaces. |
|
Auto-Rejoin Settings |
|
|
Cluster Interface |
Shows the auto-rejoin settings after a cluster control link failure. |
|
Attempts |
Between -1 and 65535. The default is -1 (unlimited). Sets the number of rejoin attempts. |
|
Interval Between Attempts |
Between 2 and 60. The default is 5 minutes. Defines the interval duration in minutes between rejoin attempts. |
|
Interval Variation |
Between 1 and 3. The default is 1x the interval duration. Defines if the interval duration increases at each attempt. |
|
Data Interfaces |
Shows the auto-rejoin settings after a data interface failure. |
|
Attempts |
Between -1 and 65535. The default is 3. Sets the number of rejoin attempts. |
|
Interval Between Attempts |
Between 2 and 60. The default is 5 minutes. Defines the interval duration in minutes between rejoin attempts. |
|
Interval Variation |
Between 1 and 3. The default is 2x the interval duration. Defines if the interval duration increases at each attempt. |
|
System |
Shows the auto-rejoin settings after internal errors. Internal failures include: application sync timeout; inconsistent application statuses; and so on. |
|
Attempts |
Between -1 and 65535. The default is 3. Sets the number of rejoin attempts. |
|
Interval Between Attempts |
Between 2 and 60. The default is 5 minutes. Defines the interval duration in minutes between rejoin attempts. |
|
Interval Variation |
Between 1 and 3. The default is 2x the interval duration. Defines if the interval duration increases at each attempt. |
Note | If you disable the system health check, fields that do not apply when the system health check is disabled will not show. |
You can change these settings from this section.
You can monitor any port-channel ID, single physical interface ID, as well as the Snort and disk-full processes. Health monitoring is not performed on VLAN subinterfaces or virtual interfaces such as VNIs or BVIs. You cannot configure monitoring for the cluster control link; it is always monitored.
Procedure
Step 1 | Choose . |
Step 2 | Next to the cluster you want to modify, click Edit ( |
Step 3 | Click Cluster. |
Step 4 | In the Cluster Health
Monitor Settings section, click Edit ( |
Step 5 | Disable the system health check by clicking the Health Check slider . 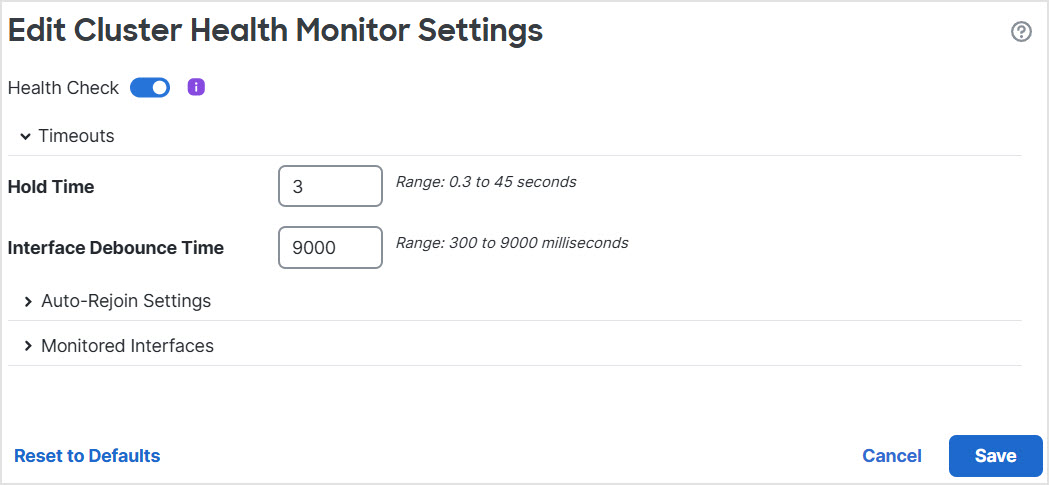
When any topology changes occur (such as adding or removing a data interface, enabling or disabling an interface on the node or the switch, or adding an additional switch to form a VSS or vPC or VNet) you should disable the system health check feature and also disable interface monitoring for the disabled interfaces. When the topology change is complete, and the configuration change is synced to all nodes, you can re-enable the system health check feature and monitored interfaces. |
Step 6 | Configure the hold time and interface debounce time.
|
Step 7 | Customize the auto-rejoin cluster settings after a health check failure. 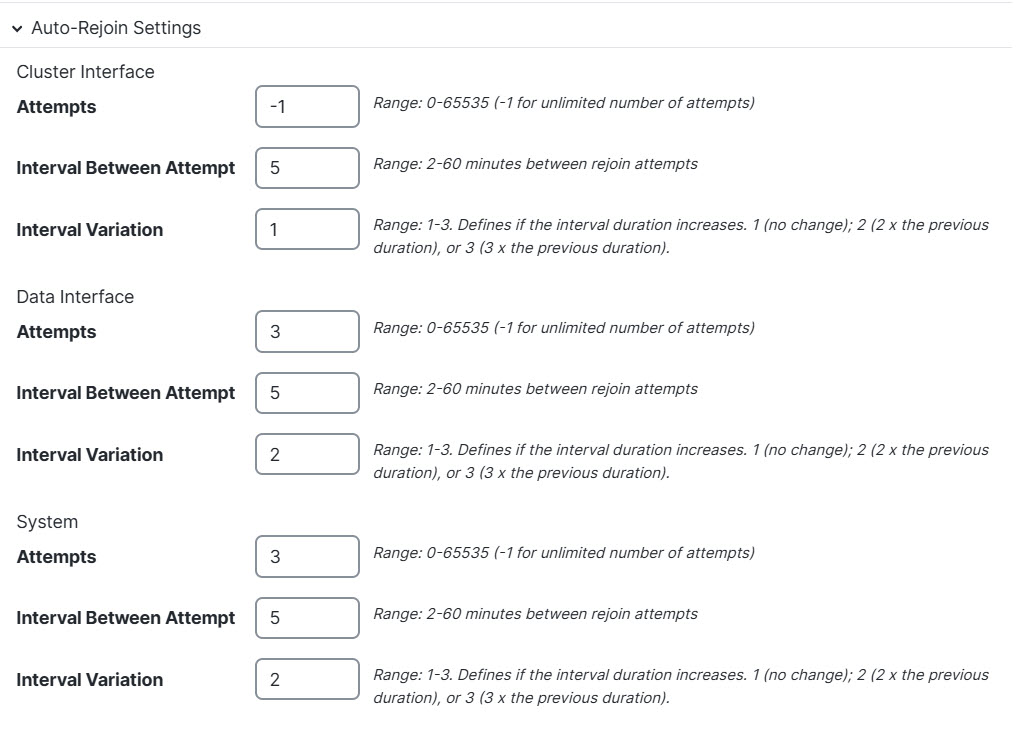
|
Step 8 | Configure monitored interfaces by moving interfaces in the Monitored Interfaces or Unmonitored Interfaces window. You can also check or uncheck Enable Service Application Monitoring to enable or disable monitoring of the Snort and disk-full processes. 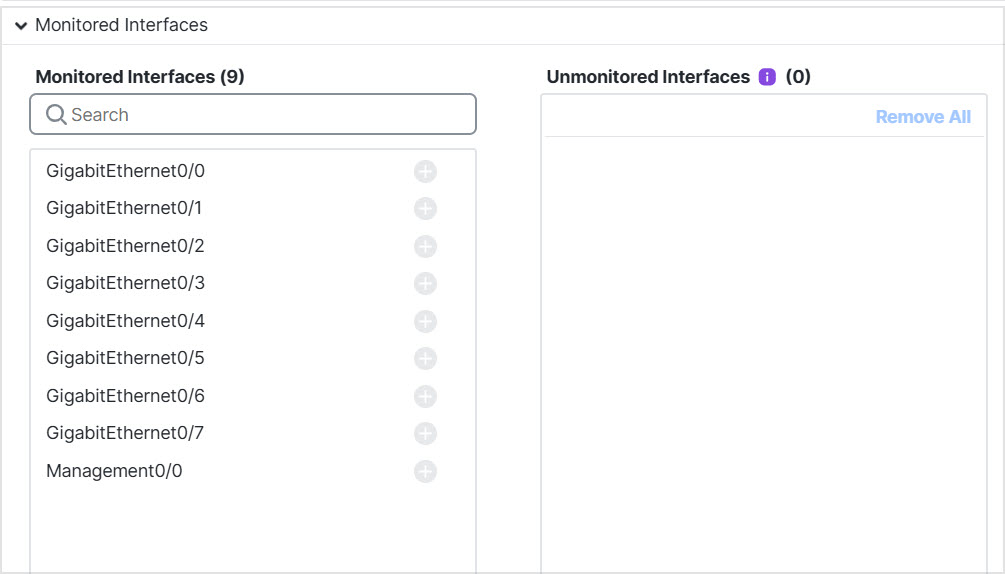
The interface health check monitors for link failures. If all physical ports for a given logical interface fail on a particular node, but there are active ports under the same logical interface on other nodes, then the node is removed from the cluster. The amount of time before the node removes a member from the cluster depends on the type of interface and whether the node is an established node or is joining the cluster. Health check is enabled by default for all interfaces and for the Snort and disk-full processes. You might want to disable health monitoring of non-essential interfaces. When any topology changes occur (such as adding or removing a data interface, enabling or disabling an interface on the node or the switch, or adding an additional switch to form a VSS or vPC or VNet) you should disable the system health check feature and also disable interface monitoring for the disabled interfaces. When the topology change is complete, and the configuration change is synced to all nodes, you can re-enable the system health check feature and monitored interfaces. |
Step 9 | Click Save. |
Step 10 | Deploy configuration changes. |